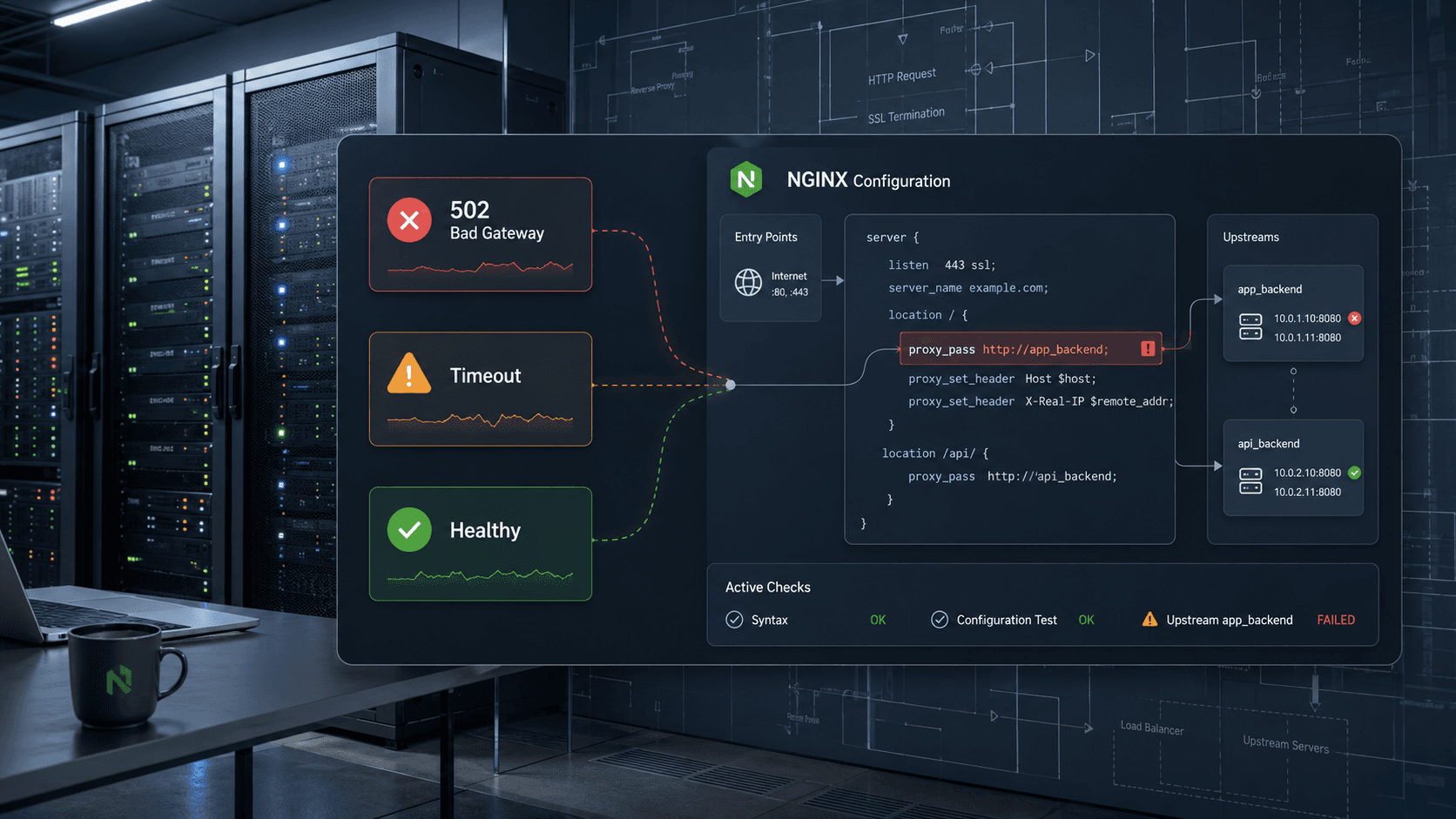
We've all been there. A new feature ships, or a minor configuration tweak is deployed, and suddenly, everything grinds to a halt. Users report 502 errors, timeouts, or worse, a completely unresponsive site. Often, the culprit lurks not in application code, but in the seemingly innocuous web server configuration.
NGINX, beloved for its speed and efficiency, is a powerful tool. However, its configuration language, while flexible, can be a minefield of subtle errors that don't immediately break the build but silently degrade performance or cause intermittent failures. These are the truly insidious problems – the ones that don't throw loud exceptions but slowly erode user trust and business operations.
The Pain of the Silent Outage
Imagine a critical business application experiencing intermittent downtime. Support tickets pile up, and the blame game begins. Developers point to the application, database admins to their systems, but the logs offer vague hints or, more frustratingly, nothing at all.
This is the hallmark of a silent NGINX configuration error. It's not a syntax error that prevents NGINX from starting; it's a logical flaw that causes it to misbehave under specific load conditions or when processing certain types of requests. This leads to a crisis where troubleshooting is difficult because the symptoms are inconsistent and the root cause is hidden in plain sight.
Diagnosing the NGINX Enigma
When faced with these elusive issues, our first step is always to meticulously examine the NGINX error logs. These logs are invaluable, even if they don't always scream the answer. We look for patterns, unusual request types, or specific error codes that might indicate a problem with how NGINX is handling connections, buffering, or proxying requests.
Common areas of concern include incorrect `proxy_pass` directives, misconfigured buffer sizes (`proxy_buffers`, `proxy_buffer_size`), or issues with SSL/TLS settings. Even seemingly minor oversights, like an improperly set `keepalive_timeout`, can lead to resource exhaustion under load.
Proactive NGINX Configuration Testing
Waiting for a production incident is a costly mistake. At Muhyo Tech, we emphasize building robust testing strategies into our deployment pipelines. For NGINX configurations, this means going beyond a simple `nginx -t` check, which only verifies syntax.
We advocate for implementing configuration linting tools that can catch common logical errors and security misconfigurations. Furthermore, integrating automated tests that simulate traffic patterns and check for expected responses is crucial. This allows us to catch potential issues in staging environments before they impact live users.
Common NGINX Pitfalls and How We Address Them
One frequent source of trouble is mismanaging upstream server health checks and load balancing. If NGINX incorrectly marks a healthy upstream server as down, it can overload the remaining servers, leading to performance degradation or complete failure.
We approach this by carefully configuring `upstream` blocks, utilizing health check directives, and setting appropriate `max_fails` and `fail_timeout` values. Understanding the interplay between these settings and the application's own resilience is key to building a stable system.
Another common pitfall is inefficient caching configuration. An improperly configured cache can lead to excessive load on the backend application, as NGINX might not be serving cached assets effectively. We spend time tuning `proxy_cache_path` and related directives to ensure optimal cache hit rates.
Buffer overflows are also a silent killer. If NGINX receives a response from an upstream server that is larger than its configured buffer, it can lead to errors. We meticulously review `proxy_buffers` and `proxy_buffer_size` directives, adjusting them based on the typical response sizes of the backend application.
The Tradeoffs: Speed vs. Robustness
There's always a tradeoff between aggressive performance tuning and absolute robustness. For instance, reducing buffer sizes might slightly improve memory usage but increases the risk of buffer overflows if upstream responses are unexpectedly large.
Our engineering philosophy at Muhyo Tech is to find the right balance for each project. We prioritize stability and reliability, especially for critical business applications. This means sometimes accepting a marginal performance hit in exchange for significantly reduced risk of downtime and unpredictable behavior.
This diligent approach to configuration management directly translates to business value. It means fewer emergency patches, less developer time spent firefighting, and ultimately, a more reliable user experience. For founders, this translates to predictable operational costs and increased customer trust.
Building for Resilience: Our Approach
When we design web application architectures, NGINX configuration is treated with the same rigor as application code. We treat the configuration files as code, meaning they are version-controlled, reviewed, and tested.
This practice ensures that we can easily roll back to a known good configuration if an issue arises. It also provides a clear audit trail of all changes made to the server's behavior, which is invaluable for debugging and compliance.
We also implement comprehensive monitoring for NGINX. This includes tracking key metrics like request rates, error rates, connection counts, and response times. Setting up alerts for anomalies allows us to detect potential configuration-related issues early, often before they manifest as user-facing problems.
For complex setups involving multiple NGINX instances or advanced routing, we often leverage tools that help manage and deploy configurations consistently across the fleet. Automation here reduces the chance of human error, a primary cause of subtle misconfigurations.
The Long-Term Value of NGINX Vigilance
Investing time in understanding and properly configuring NGINX pays dividends. It underpins the reliability and performance of the entire web application stack. A well-tuned NGINX instance acts as a robust front door, efficiently handling traffic and protecting backend services.
This vigilance ensures that our clients' digital services remain available, performant, and secure. It reduces operational stress, allowing businesses to focus on their core activities rather than wrestling with infrastructure problems. It’s a foundational element of building scalable and dependable digital systems.