The memory of that launch still sends a shiver down our collective spine. We had built what we thought was a robust Node.js backend, meticulously tested, ready for prime time. Then, the traffic hit, a wave far beyond our projections, and our carefully crafted system began to groan, then buckle.
It wasn't a slow degradation; it was a sudden, terrifying collapse. Latency spiked, requests timed out, and the dashboard became a sea of angry red alerts. That day forced us to confront some harsh realities about Node.js scaling in production, and we learned lessons the hard way.
The Illusion of Single-Threaded Simplicity
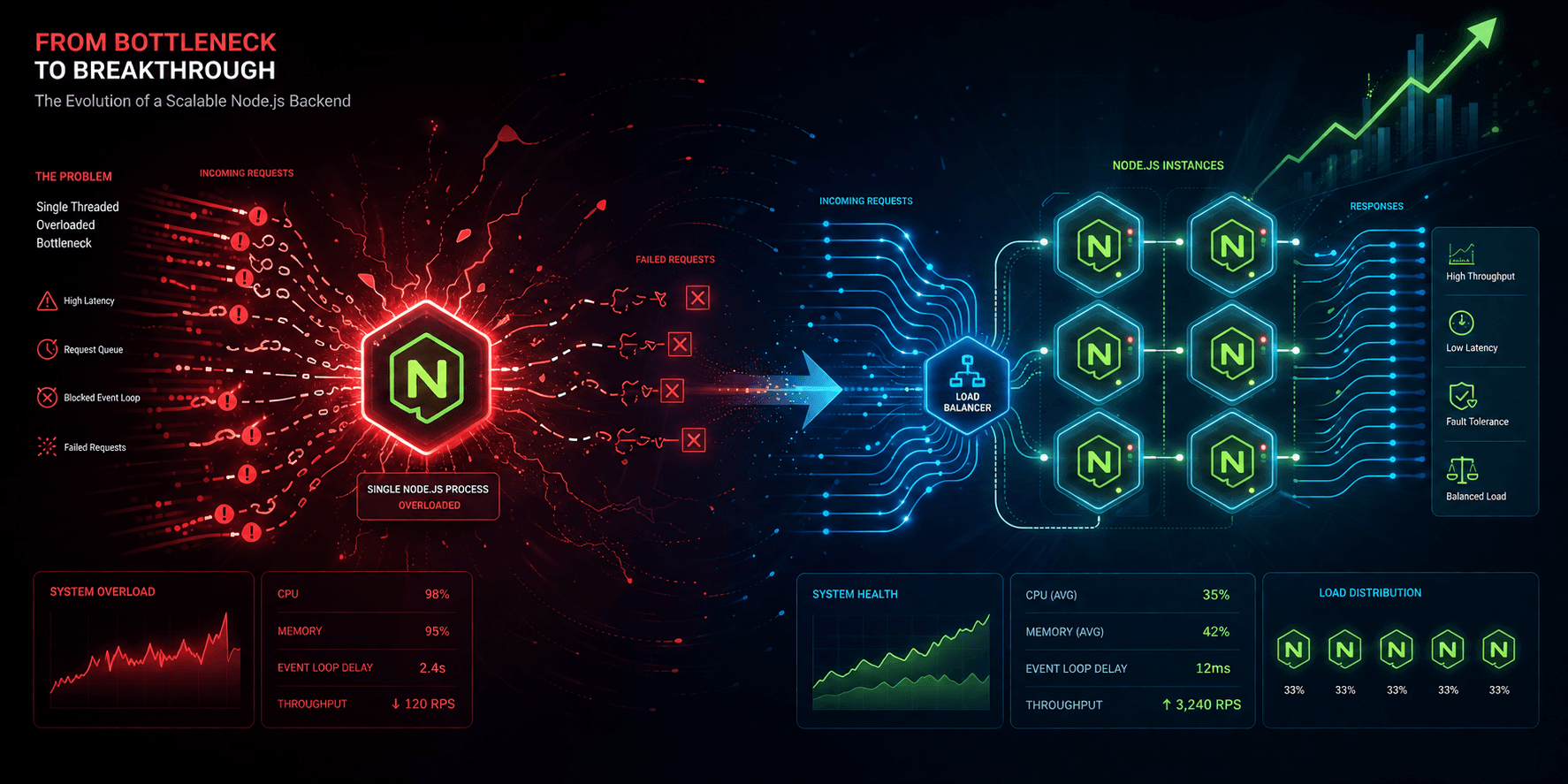
Node.js is fantastic for I/O-bound operations, and its single-threaded, event-driven model often feels like a superpower. For a long time, we leaned into this strength, enjoying the development speed and efficiency it offered.
However, that single thread becomes a critical bottleneck when CPU-intensive tasks enter the picture. A complex data transformation, a heavy cryptographic operation, or even inefficient JSON parsing can block the entire event loop. Our launch exposed this vulnerability brutally, freezing our entire application for users.
Lesson 1: Don't Trust One Core – Go Cluster
Our first frantic fix involved leveraging the Node.js cluster module, or more practically, using PM2. This isn't groundbreaking, but in the heat of the moment, realizing we hadn't properly deployed multiple processes per server felt like a punch to the gut.
Running multiple Node.js instances, one per CPU core, immediately distributed the load and gave us breathing room. It allowed our application to handle multiple concurrent requests without one CPU-bound task holding everything hostage. We quickly learned that a single Node.js process is almost never enough for any serious production workload.
Lesson 2: Statelessness Isn't Just a Buzzword
As we scaled horizontally by adding more servers, the concept of statelessness moved from an architectural best practice to an absolute necessity. Our initial design had some lingering state tied to individual server processes, a relic from simpler times.
Users were experiencing intermittent issues, dropping sessions, or seeing inconsistent data because their requests might hit a different server on subsequent calls. We had to aggressively refactor to ensure every request was self-contained, with session management and data storage externalized to Redis or a shared database. This move was painful but utterly transformative for our scalability.
Lesson 3: Offload, Offload, Offload – The Power of Queues
Even with multiple processes and stateless design, certain operations were just too heavy to execute synchronously within the request-response cycle. Generating complex reports, sending bulk emails, or processing large file uploads were still causing intermittent spikes.
We implemented a robust message queuing system, initially using Redis for simple background jobs, then migrating to RabbitMQ for more critical, durable tasks. This decoupled heavy operations from the user's immediate request, significantly improving response times and overall system stability. It shifted our mindset from immediate processing to eventual consistency, a crucial scaling pattern.
Lesson 4: The Database Is Always the Bottleneck (Eventually)
Node.js applications, being I/O heavy, spend a significant amount of time waiting on external resources, especially databases. Our database, a well-optimized PostgreSQL instance, started showing signs of strain as the Node.js tier scaled up.
We dove deep into query optimization, adding missing indexes, and carefully analyzing our ORM's generated queries. Implementing a read replica strategy for analytical queries further alleviated the primary database's load. Sometimes the Node.js application itself isn't the problem; it's simply exposing the limits of its dependencies.
Lesson 5: You Can't Fix What You Can't See – Observability is King
During the initial meltdown, we were effectively flying blind. Our basic monitoring gave us CPU and memory metrics, but it lacked the granular detail needed to pinpoint the exact bottleneck. We couldn't tell if it was the event loop, a specific route, or an external service.
This experience pushed us to invest heavily in comprehensive observability. We implemented distributed tracing, detailed custom metrics for key business logic, and robust structured logging that flowed into a centralized system. Having real-time insights into event loop lag, garbage collection activity, and individual request durations became invaluable for identifying and resolving issues before they escalated.
The Aftermath and Our New Standard
That stressful launch was a trial by fire, but it forged a more resilient team and a far more robust architecture. We learned that scaling Node.js isn't just about throwing more instances at the problem; it requires a deep understanding of its runtime, careful architectural choices, and a relentless focus on external dependencies.
At Muhyo Tech, planning for scale and building in observability are now non-negotiable from day one. We still love Node.js for its productivity and performance, but we approach its deployment with a healthy respect for its unique scaling characteristics. The scars from that launch remind us that production reality always trumps development assumptions.